Project
HPC Job Observability Service
A microservice for tracking and monitoring HPC (High Performance Computing) job resource utilization with Prometheus metrics export.
Role
HPC
Date
23-01-2026
Tech
GoDockerBashSlurm
Project
A microservice for tracking and monitoring HPC (High Performance Computing) job resource utilization with Prometheus metrics export.
HPC
23-01-2026
Highlights
The HPC Job Observability Service is a specialized microservice proof of concept (POC) designed to bring modern observability practices to High Performance Computing (HPC) environments. Traditional HPC workloads often run as "black boxes" from a metrics perspective. This service bridges that gap by integrating directly with the Slurm workload manager to provide real-time tracking of job resource utilization (CPU, Memory, GPU).
In many HPC clusters, it is difficult for administrators and users to understand exactly how resources are being utilized during a job's execution. Questions like "Is my job actually using the GPU?" or "Did my job fail because it ran out of memory?" are notoriously hard to answer without detailed, time-series metrics. Standard monitoring tools often aggregate at the host level, losing the context of individual jobs.
This project provides a complete observability pipeline that links infrastructure metrics directly to specific HPC jobs:
prolog and epilog scripts to capture job lifecycle events instantly without polling.The system follows a clean microservice architecture built with Go, designed for stability and low overhead on compute nodes.
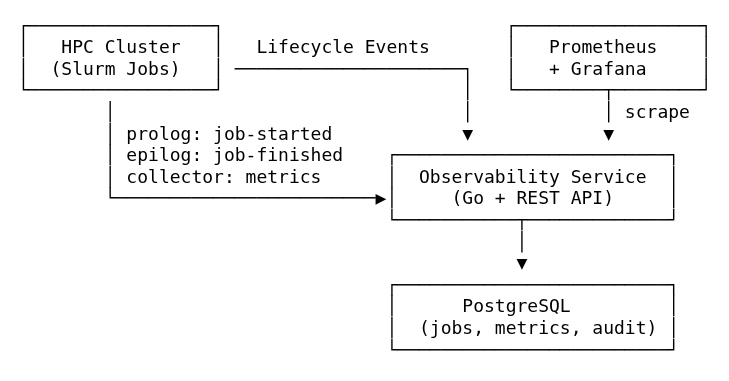
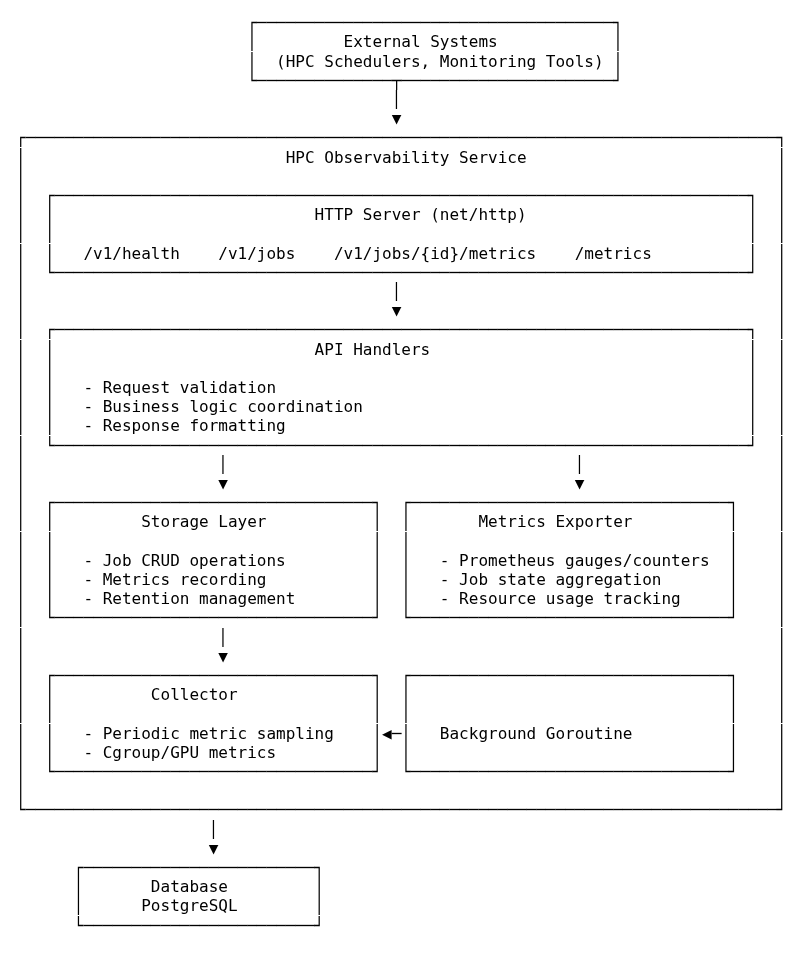
net/http and adhering to OpenAPI specifications (Design-First). It handles lifecycle events and acts as the bridge between raw system data and proper observability standards.Instead of polling Slurm (which can be slow and stressful for the scheduler), the service uses an event-based approach.
prolog script fires a webhook to the service (/v1/events/job-started).epilog script does the same (/v1/events/job-finished), capturing the exit code and signal to accurately determine if the job completed successfully, failed, or was cancelled.HPC environments frequently require traceability: who changed a job, what changed, and why. To support this, the service stores an audit trail of job lifecycle events and updates.
At a high level, each significant change to a job results in an audit event that captures:
slurm-prolog, slurm-epilog, collector, api)This makes it much easier to debug cases like "why did a job become cancelled?" or "when did we start sampling metrics for this job?" without relying on ephemeral scheduler logs.
The service pushes the boundaries of standard monitoring by collecting:
This granularity allows for detailed dashboards where users can correlate code execution phases with resource spikes.
This project follows an API-first workflow: the OpenAPI specification is treated as the source of truth, and Go types + server interfaces are generated from the spec.
In practice, that means the development loop looks like:
go generate ./...)The benefits are substantial for a microservice that needs to stay maintainable:
This tool provides a "glass box" view into HPC jobs, enabling:
Once metrics are exported in Prometheus format, Grafana dashboards can provide an immediate “single pane of glass” for both job-level and node-level resource behavior.
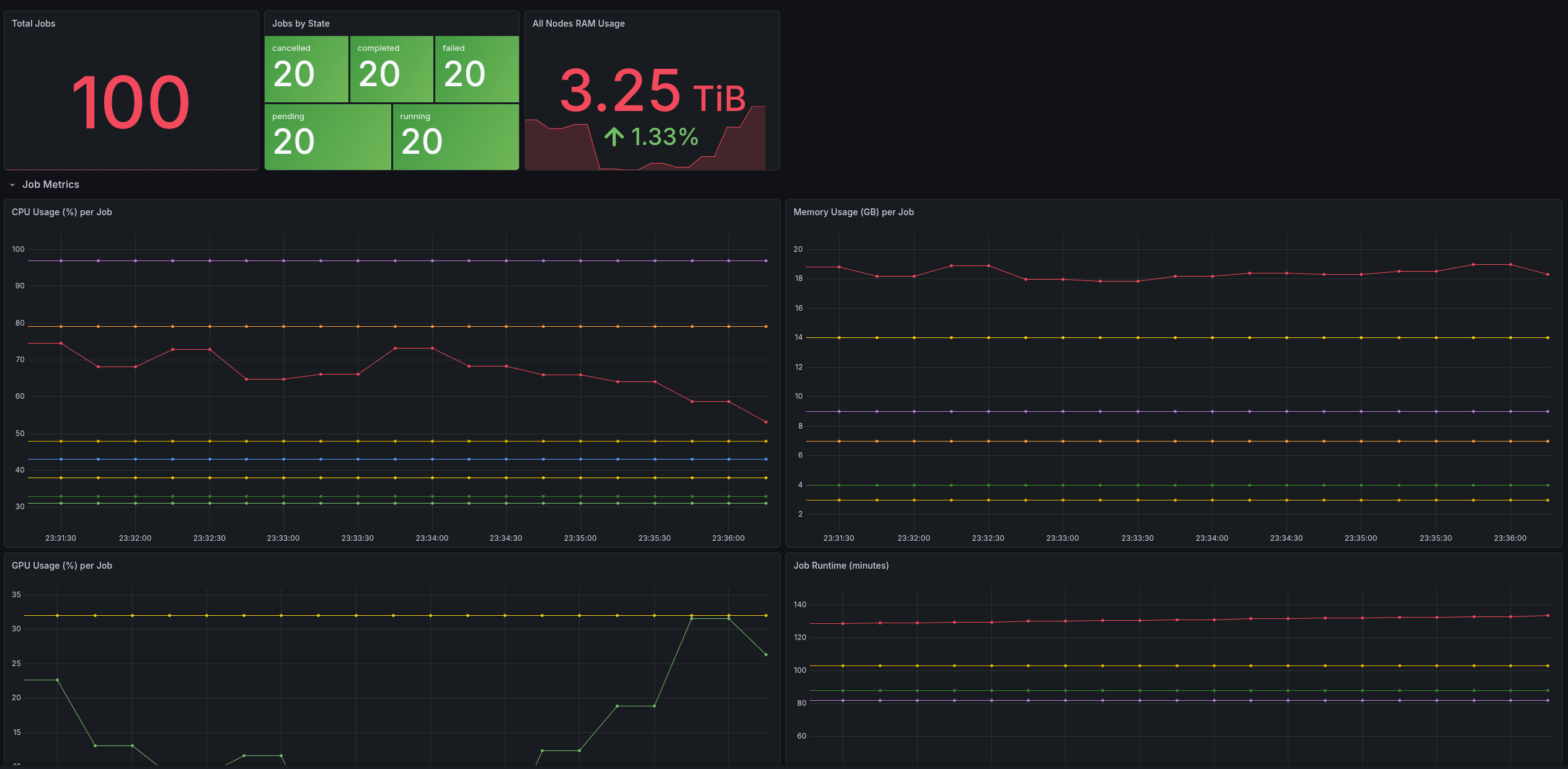
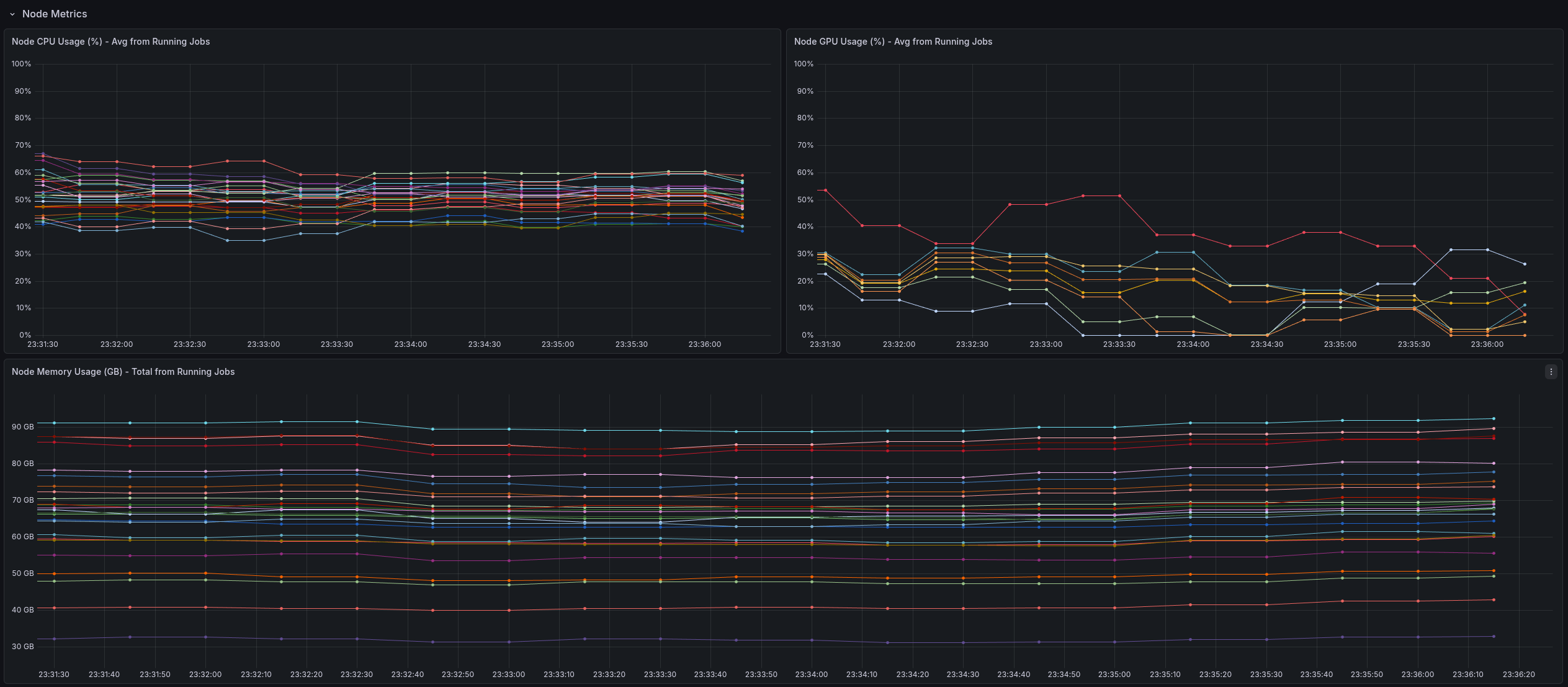
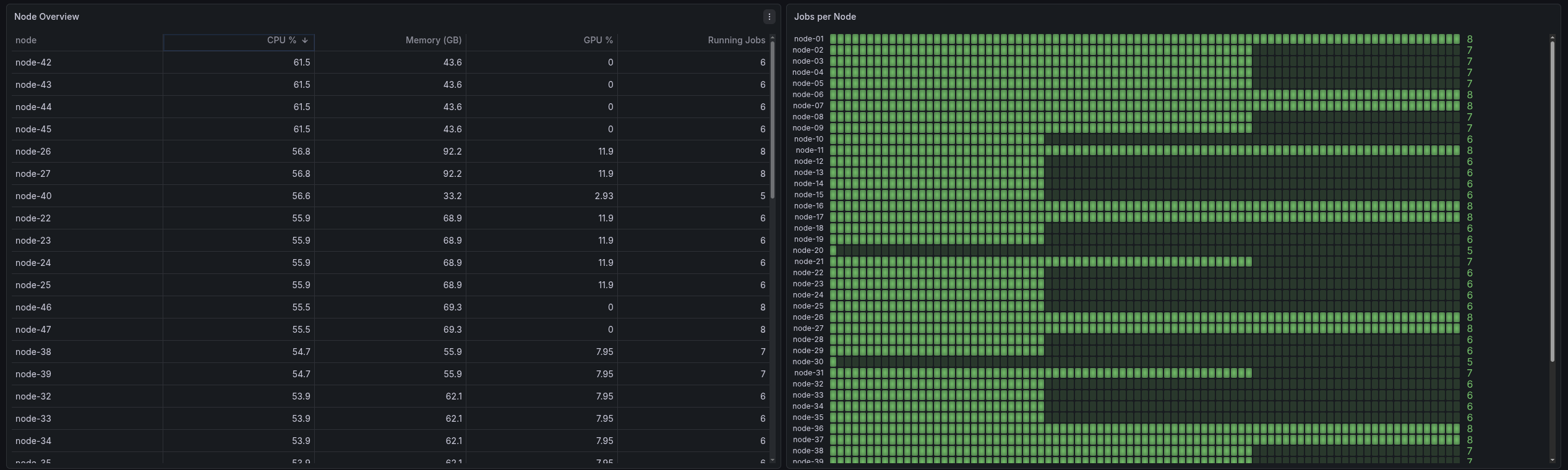
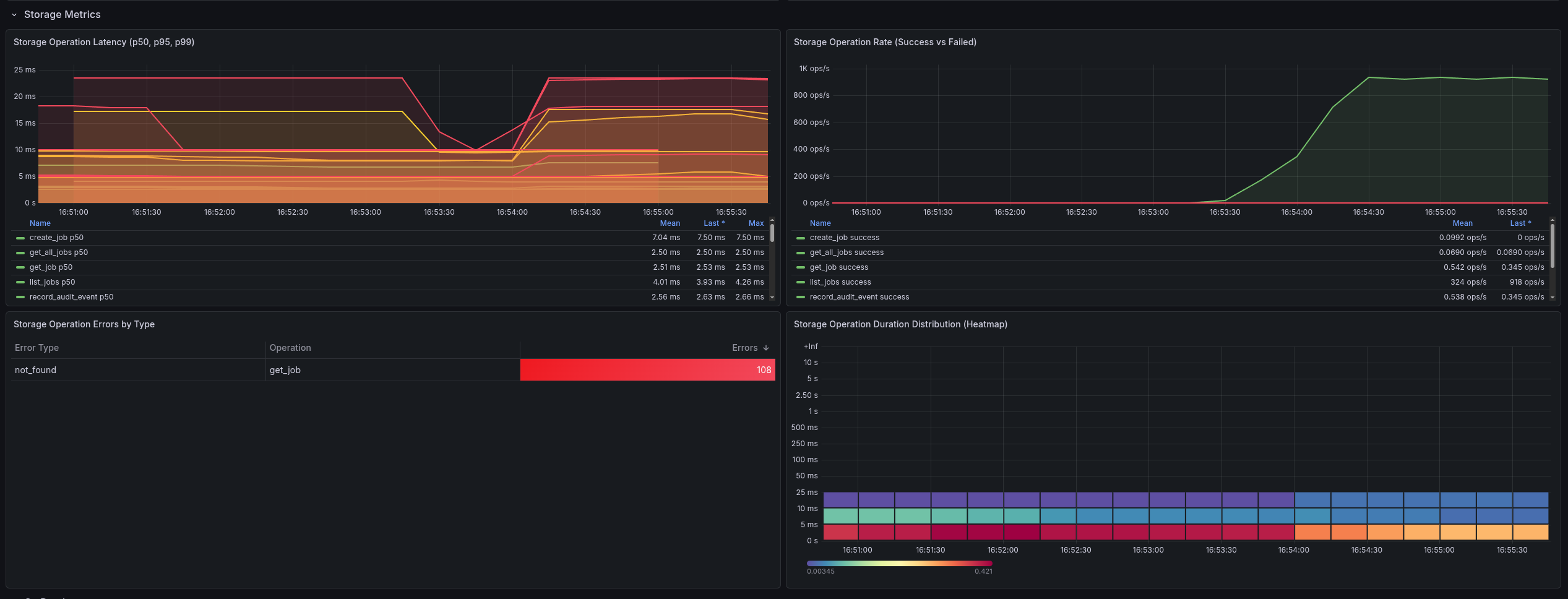
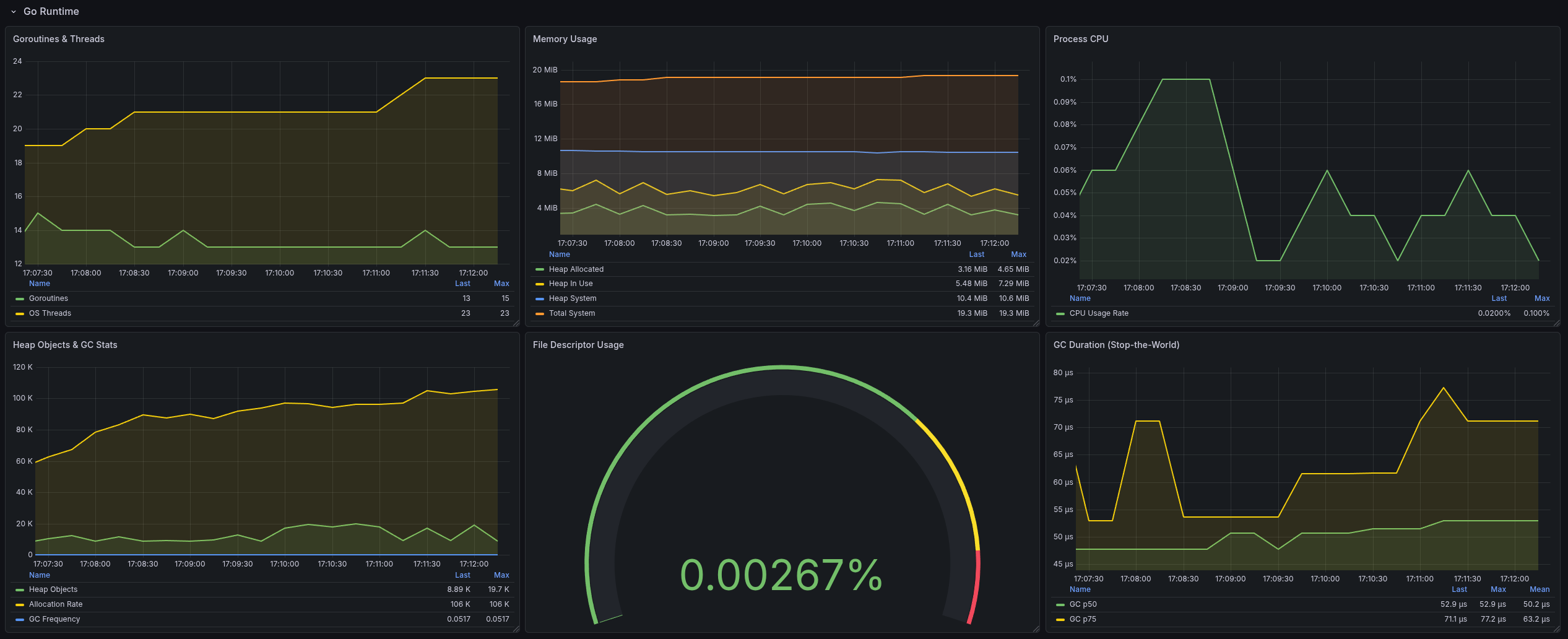
This service is intentionally a proof of concept, focused on validating the architecture and data flow rather than being a hardened, production-complete platform.
There are plenty of directions to take it further: stronger auth and multi-tenancy, deeper scheduler integrations, more robust error handling and backpressure, richer GPU accounting, and more production-grade deployment and operational tooling.
It's not a perfect complete solution today, but it's a strong foundation that could be used to develop something even better.